1st Year of the Project / Intermediate Results Presentation
Natural language processing (NLP) tools are used to detect words and phrases expressing location and time. The NLP task used to detect these spatio-temporal expressions is called “named entity recognition” (NER). UGESCO’s NER task differs in various aspects from previous NER projects, involving a number of challenges related to the nature and the type of texts used for picture descriptions and the types of enrichments required for geo-temporal named entity recognition.
Originally, NER was limited to the detection of proper nouns referring to names of persons, organizations and locations, but the categories were later on extended to other types, including numerical information (referring to time, date and different numbering systems). In UGESCO, we limit NER to two main categories: location and time. The location category is expanded from the general LOC type (referring to any type of location, including names of cities, regions or countries) to a set of subcategories, including POIs[1]. The following LOC subcategories are used: PLACE, STREET, ROAD, WATERWAY, BUILDING, SPACE and MONUMENT. In the case of timestamps, the TIMEX[2] categories are used. This subcategorization typology facilitates fine-grained selection of locations and time.
The main issue of NER processing in the UGESCO project is the brevity and the structure of the photo descriptions. Unlike ordinary running text, text samples describing pictures are usually short texts, lacking co-textual information, necessary to disambiguate the words. Moreover, description fields often have a reduced syntactic structure (e.g. subject missing, use of infinitives), so that specific training and/or adaptation of existing NLP tools is required.
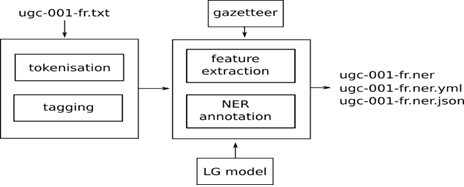
Figure 3 gives a schematic overview of the different steps used in the NER processing. As an example, we use a French input text (ugc-001-fr.txt), but the same approach is used for texts in any other language. First of all, some pre-processing is required: the text is cleaned, tokenized and tagged. Tokenization involves the process of separating words from non-words (e.g. punctuation). Each token is then assigned a part-of-speech tag, indicating the word category, so that you can distinguish verbs from nouns or any other word category. After pre-processing the tokens, the NER process can start, using two extra inputs: the language model (LG) and a gazetteer. The LG model is the result of a supervised training process, based on previously annotated data and template based algorithm for NER detection. The gazetteer is principally a kind of location dictionary, containing a set of commonly used locations. On the basis of these extra resources, the NER process detects named entities in the text samples.
The result of the NER process is stored in an output file (ugc-001-fr.ner), and in two extra files in a special format (output ending in yml and json), which enables further processing by other tools.
NER processing of picture labels
[1] points-of-interests, such as names of specific buildings, roadways and important landmarks