1st Year of the Project / Intermediate Results Presentation
In case NER is not able to detect the exact location of a particular image (or in case we want to validate the NER output) we can detect the location (or some of its features) by using one of the computer vision based geolocalization algorithms that have been proposed in literature. Feature matching with georeferenced image datasets is by far the most useful/accurate geolocalization technique. Based on a feature point matching algorithm, this algorithm searches the best match of the POI image within a dataset of georeferenced images that are taken in the POI neighborhood. However, such georeferenced dataset will not always be available or it will be computationally too hard to build it up for an entire region/city. For this reason, we introduce a place recognition filtering step based on semantic scene understanding. The generated semantic features facilitate the construction of a georeferenced dataset. The approach that is most closely related to our setup is the hierarchical, multi-modal approach of Kelm et al. for georeferencing Flickr videos. Both textual toponym identification in video metadata and visual features of the video key frames are used to identify similar content. Their approach, however, is still global and the accuracy is rather limited, i.e., only one third of the video dataset is correctly geotagged within a 1 km error margin, which is too limited for UGESCO’s desired search relevance and querying efficiency and effectivity.
Semantic scene understanding for place recognition. Visual scene recognition is a trending topic since last few years. Previous studies heavily focused on feature engineering where features are generated based on statistical analysis, previous knowledge and feature performance evaluation. This requires expensive human labour and mostly relies on expert knowledge. A more recent trend is to use feature learning techniques where different positive and negative samples are shown to the system and, based on these examples, the parameters of the network are changed accordingly. As discussed in [7], feature learning mechanisms achieve outstanding results compared to handcrafted features for different localization tasks, which is also the reason for using it in UGESCO. A trained convolutional neural network (CNN) such as Places365-VGG[1] is able to give scene predictions and their corresponding prediction confidence [8]. In combination with a semantic vocabulary and appropriate semantic distance measures, this allows us to fine-tune and determine the context of the scene.
UGESCO’s place recognition tool tags each image with a set of semantic descriptors using the MIT places model[2]. The Places model suggest the most likely place categories representing the image, using Places-CNN, and identifies if the image is an indoor or an outdoor place. The indoor/outdoor information is also used to select the correct mode (indoor/outdoor) in the Street View mapping and rephotography. The output of the places model can also be used for data filtering and picture grouping. In the CegeSoma collection, for example, we can easily filter out pictures that do not contain location clues or we can group pictures based on semantic concepts (such as building types like churches and castles). In order to improve the image categorization, we will also analyze the co-occurrence of semantic concepts. The figure below shows the output of the place recognition on some pictures of the CegeSoma collection. This output can be further optimized by also taking into account semantic relationships between the suggested keywords.

Place recognition results – pictures from CegeSoma Collection.
Street view scraping and matching. Depending on the metadata output of the NER and computer vision modules, different strategies for Street View matching have been developed to find the exact location of an image if we only have its city or street name. If, for example, NER tells us the street and city name, we can request/extract an Open Street Map (OSM) street polygon, process the Street View (SV) panorama images of this region (to create a SV dataset), filter the SV dataset on semantic similarity (based on places output – or other CNNs) and match the query image to the SV dataset (as shown in the figure below). Of course, NER and computer vision output will not always be able to give such detailed location estimation. If, for example, we only know that it is a church in Ghent, we will first query DBpedia[3] for all churches in Ghent and use address geocoding to build up the SV datasets of all possible candidates. If we don’t know the city, or we can’t find a good match, we will try to get more detailed information from the named entity disambiguation step or collect crowdsourced contributions of the particular image.
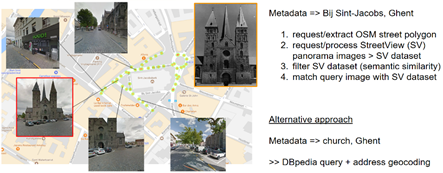
Streetview scraping – matching with georeferenced dataset.
[1] http://places.csail.mit.edu/
[2] http://places2.csail.mit.edu/
[3] https://wiki.dbpedia.org/